How Does the Genome Work? – Part 2 of 5
Part 2 — The Cell as Hardware
The Machine That Reads the Code
Part 1 described the genome as executable code — a 3.2-billion-base-pair program written in a four-letter alphabet, organized into callable subroutines with conditional logic, alternative outputs, and error-correcting redundancy. But code does nothing without a machine to read it. A hard drive sitting on a table is inert. The information it contains becomes operational only when a processor loads the instructions, decodes them, and executes them in a physical environment with power, memory, input channels, and output pathways.
The cell is that machine.
Every living cell contains a complete hardware platform capable of reading the genome's instructions, manufacturing the specified products, delivering them to the correct locations, and responding to environmental inputs — all while maintaining its own structural integrity, generating its own power, and replicating the entire system when instructed to divide. In any free-living cell, no major component of this machinery is optional. Remove the ribosomes, the membranes, the energy systems, or the transport networks and the cell dies. The machine is irreducibly integrated — not in the abstract sense of a thought experiment, but in the empirically observed sense that free-living cells lacking any of these subsystems do not survive.
What follows is a component-by-component description of the cell's hardware, mapped to the computing architecture it mirrors.
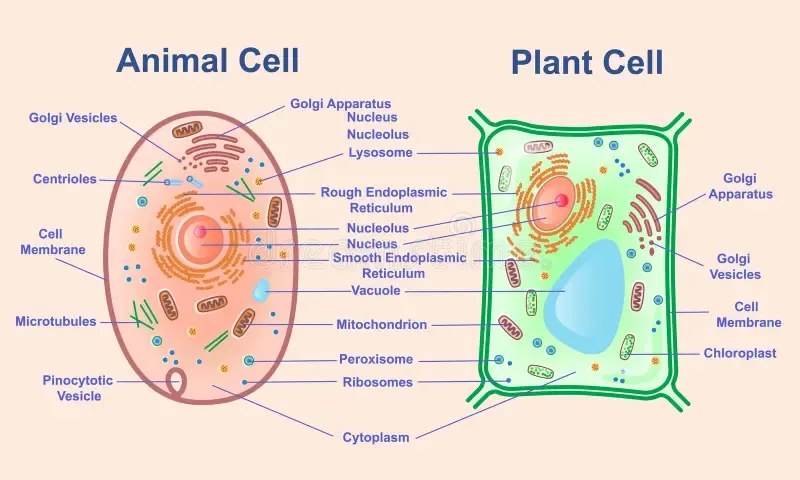
The Processor: Ribosomes
The ribosome is the cell's central processing unit. Its function is translation — the physical conversion of a coded instruction sequence (mRNA) into a functional product (protein). Every protein the cell uses — structural, enzymatic, regulatory, defensive — is manufactured by a ribosome reading an mRNA transcript and assembling the specified amino acid chain one residue at a time.
A ribosome is a molecular machine approximately 25 nanometers in diameter, composed of two subunits: the large subunit and the small subunit. Together they contain approximately 80 proteins and 4 ribosomal RNA (rRNA) molecules, totaling roughly 4.2 megadaltons of molecular mass. Despite this complexity, the ribosome performs a single, precisely defined operation: it reads a codon (three-base instruction word) from the mRNA template, matches it to the correct amino acid via a transfer RNA adapter, and catalyzes the formation of a peptide bond linking that amino acid to the growing protein chain.
The processing speed is approximately 15-20 amino acids per second in eukaryotic cells. A typical 300-amino-acid protein is assembled in roughly 15-20 seconds. The error rate is approximately 1 misincorporation per 10,000 amino acids — a fidelity of 99.99%. This is comparable to the bit-error rates in modern digital communication channels, achieved by a molecular machine operating in an aqueous solution at 37 degrees Celsius.
A single human cell contains approximately 10 million ribosomes. This is not a single processor. It is a massively parallel processing array, with millions of ribosomes simultaneously translating thousands of different mRNA transcripts. The cell's protein output — its proteome — is the aggregate product of this parallel computation, running continuously.
In computing terms, the ribosome is a hardwired instruction decoder and assembler. It does not interpret the code. It does not make decisions about what to build. It reads the instruction it is given and executes it with high fidelity. The decisions about which instructions to send to the ribosomes are made upstream, by the regulatory architecture described in Part 1 — the promoters, enhancers, transcription factors, and splicing machinery that determine which genes are transcribed into mRNA in the first place. The ribosome is the factory floor. The genome is the engineering office.
The Instruction Decoder: Transfer RNA
The ribosome reads codons, but codons are nucleic acid sequences and proteins are amino acid sequences. These are chemically unrelated languages. Something must bridge the gap — a physical adapter that reads one language on one end and presents the corresponding symbol in the other language at the other end.
Transfer RNA (tRNA) is that adapter. Each tRNA molecule is a small RNA structure, approximately 75-90 nucleotides long, folded into a characteristic L-shape with two functional ends. One end carries an anticodon — a three-base sequence complementary to a specific mRNA codon. The other end carries the amino acid specified by that codon. When the ribosome encounters a codon in the mRNA, the matching tRNA binds via its anticodon, and the ribosome transfers the amino acid from the tRNA to the growing protein chain.
The tRNA is, in the most precise sense, a physical lookup table — the hardware implementation of the genetic code. The codon-to-amino-acid mapping described in Part 1 is not an abstraction. It is physically embodied in the structure of the tRNA molecules and the enzymes that charge them. Each tRNA is loaded with its correct amino acid by a specific enzyme called an aminoacyl-tRNA synthetase. There are 20 of these enzymes — one for each amino acid — and each one must recognize both its specific amino acid and the correct set of tRNA molecules that carry codons for that amino acid. The synthetase is the gatekeeper that ensures the lookup table is loaded correctly.
If any synthetase loads the wrong amino acid onto a tRNA, every protein made from that point forward will contain errors at every position where that amino acid appears. The fidelity of the entire system depends on 20 independent molecular recognition events, each operating with error rates below 1 in 10,000. This is not redundancy. It is a precision-critical interface between two information domains — nucleic acid and protein — mediated by dedicated hardware.
In computing terms, the tRNA system is the machine-language decoder. It sits between the stored program (mRNA) and the physical output (protein), converting abstract instruction codes into concrete physical actions. Without it, the code cannot be executed. Without the synthetases, the decoder cannot be loaded. The decoder and its loading system are themselves encoded in the genome — the code specifies the hardware that reads the code. This circularity is the subject of Part 4.
The Program in Memory: Messenger RNA
DNA is the master copy — the archival storage. It resides in the nucleus, protected by a double membrane, wrapped around histone proteins, and accessed only through regulated transcription. DNA is not read directly by the ribosomes. Instead, a working copy of each needed gene is transcribed into messenger RNA (mRNA) and exported from the nucleus to the cytoplasm where the ribosomes operate.
mRNA is the program loaded into active memory. It is a single-stranded copy of a gene's coding sequence, carrying the instructions from the nucleus to the ribosome in a format the ribosome can read. It is produced on demand, transported to the execution site, read one or more times, and then degraded. Its lifespan is typically minutes to hours — long enough to produce the needed proteins, short enough to allow the cell to change its program rapidly in response to new conditions.
The analogy to computing architecture is direct. DNA is the hard drive — permanent, high-capacity, archival storage. mRNA is the contents of RAM — volatile, temporary, loaded from storage as needed, discarded when the task is complete. The nucleus is the secure server room. The nuclear pore complexes — large protein structures embedded in the nuclear membrane that control what enters and exits the nucleus — are the access-control layer, inspecting every molecule that passes through.
This separation of storage from execution is a fundamental principle in computing architecture, and it exists in the cell for the same reason it exists in computers: the archival copy must be protected from the wear and tear of active use. DNA replication and repair occur in the controlled environment of the nucleus. Protein synthesis occurs in the bustling cytoplasm. The two environments are physically separated, connected only by the regulated export of mRNA transcripts through the nuclear pores. The architecture is designed to protect the master copy while allowing rapid, flexible execution of its instructions.
The Power Supply: Mitochondria
Every computational operation requires energy. In digital computers, the power supply converts electrical energy from the wall outlet into the precise voltages required by the processor, memory, and storage systems. Without power, the hardware is inert.
In the cell, mitochondria are the power supply. These are membrane-bound organelles — typically 1-10 micrometers long, present in hundreds to thousands per cell — that convert chemical energy (from glucose and fatty acids) into adenosine triphosphate (ATP), the universal energy currency of the cell. Every energy-requiring process — protein synthesis, DNA replication, DNA repair, active transport, cytoskeletal movement, signal transduction — is powered by ATP hydrolysis.
The conversion process is oxidative phosphorylation, a sophisticated electron transport chain embedded in the inner mitochondrial membrane. Electrons from metabolized nutrients are passed through a series of protein complexes (Complexes I through IV), each transfer releasing energy that is used to pump hydrogen ions across the membrane. The resulting electrochemical gradient drives ATP synthase — a rotary molecular motor that physically spins as it catalyzes the formation of ATP from ADP and inorganic phosphate. ATP synthase rotates at approximately 100-150 revolutions per second, producing roughly 3 ATP molecules per rotation. A single cell produces and consumes approximately 10 billion ATP molecules per second.
The parallel to a power supply is structural, not metaphorical. The electron transport chain is a voltage converter — stepping down the energy from high-energy electrons to the precise, usable packets (ATP) that the rest of the cell requires. ATP synthase is a turbine. The proton gradient is the voltage differential. The inner mitochondrial membrane is the insulation that maintains the gradient. Every element has a direct functional equivalent in electrical power engineering.
Mitochondria carry their own small genome — approximately 16,500 base pairs encoding 37 genes, primarily for components of the electron transport chain. The remaining mitochondrial proteins — roughly 1,000-1,500 — are encoded in the nuclear genome, manufactured by cytoplasmic ribosomes, and imported into the mitochondria via dedicated transport complexes. This dual dependency means mitochondrial function requires coordination between two separate genomes in two separate compartments — another layer of system integration. Mitochondrial DNA has weaker error-correction systems than nuclear DNA, and its mutation rate is approximately 10-17 times higher. This makes mitochondrial function one of the first systems to degrade as copying errors accumulate — a point of direct relevance to the project's broader analysis of biological decline.
The Fabrication Plant: Endoplasmic Reticulum
Ribosomes synthesize proteins, but a newly synthesized protein chain is not yet a functional product. It must be folded into its correct three-dimensional structure, chemically modified (glycosylation, phosphorylation, disulfide bond formation), quality-checked for proper folding, and routed to its correct destination — the cell surface, a specific organelle, the extracellular environment, or the cytoplasm.
The endoplasmic reticulum (ER) is the fabrication and quality-control facility that performs these post-translational operations. It is a continuous membrane network extending from the nuclear envelope throughout the cytoplasm, with a total surface area that exceeds the cell's outer membrane by an order of magnitude or more.
The ER has two functional regions. The rough ER is studded with ribosomes on its cytoplasmic face — these are the ribosomes that synthesize proteins destined for membranes, secretion, or organelles. As the ribosome translates the mRNA, the growing protein chain is threaded directly into the ER lumen, where chaperone proteins assist in folding and quality-control enzymes verify the result. Misfolded proteins are tagged for degradation — a reject system that prevents defective products from reaching their destinations.
The smooth ER handles lipid synthesis, steroid hormone production, calcium storage, and detoxification. In liver cells, smooth ER enzymes metabolize drugs and toxins. In muscle cells, specialized smooth ER (sarcoplasmic reticulum) stores and releases calcium to control contraction.
In computing terms, the rough ER is the post-processing and quality-assurance pipeline. The ribosome produces the raw output. The ER folds, modifies, inspects, and certifies it. Defective outputs are caught and recycled before they can cause damage downstream. This is not optional functionality — without ER quality control, misfolded proteins aggregate and kill the cell. The fabrication plant is as essential as the processor.
The Packaging and Shipping Department: Golgi Apparatus
Products that pass ER quality control are packaged into transport vesicles — small membrane-bound containers — and shipped to the Golgi apparatus. The Golgi is a stack of flattened membrane sacs (cisternae), typically 4-8 per stack, organized into a receiving face (cis, nearest the ER) and a shipping face (trans, nearest the cell membrane).
As products move through the Golgi stack from cis to trans, they undergo further modification — additional glycosylation, sulfation, proteolytic cleavage — and are sorted for delivery. The Golgi reads molecular address tags on each protein and routes it to the correct destination: the cell surface, a lysosome, a secretory vesicle for export, or back to the ER if further processing is needed.
This is a logistics system. The Golgi receives products from the fabrication plant, applies finishing modifications, reads the shipping label, and routes the package to the correct dock. The vesicles that bud from the trans-Golgi carry specific coat proteins (clathrin, COPI, COPII) that determine their destination — a physical addressing system comparable to packet headers in network communication.
The accuracy of this sorting is critical. A lysosomal enzyme delivered to the cell surface instead of the lysosome would digest the cell's own extracellular matrix. A secretory protein retained inside the cell would fail to perform its extracellular function. The Golgi handles thousands of distinct products simultaneously, routing each one correctly based on its molecular address tag. The error rate is extremely low, though not zero — and when it fails, the consequences are specific, traceable diseases (I-cell disease, for example, results from a single enzyme deficiency in Golgi-based address tagging).
The Transport Network: Cytoskeleton
The cell is not a bag of freely diffusing molecules. It is a structured environment with an internal transport network — the cytoskeleton — that moves cargo between specific locations with directional precision.
The cytoskeleton consists of three filament systems:
Microtubules are the highways. These are hollow tubes, 25 nanometers in diameter, assembled from tubulin protein subunits. They radiate outward from the centrosome (near the nucleus) to the cell periphery, providing long-range transport tracks. Motor proteins — kinesin (moving toward the cell periphery) and dynein (moving toward the nucleus) — walk along microtubules carrying cargo vesicles, organelles, and mRNA transcripts. The transport is directional, ATP-powered, and specific: each motor protein carries a defined cargo determined by adapter proteins that link the motor to its payload.
Actin filaments (microfilaments) are the local roads. These are thin, flexible filaments, 7 nanometers in diameter, concentrated near the cell surface. They drive cell shape changes, membrane protrusions, and short-range transport. Myosin motor proteins walk along actin filaments carrying cargo for local delivery.
Intermediate filaments are the structural framework. These provide mechanical strength and resistance to shear stress — the cell's structural steel.
In computing terms, the cytoskeleton is the system bus — the physical transport layer that connects processor (ribosome), memory (nucleus), power supply (mitochondria), fabrication (ER), packaging (Golgi), and I/O (cell membrane). Data packets (vesicles carrying proteins, lipids, or signaling molecules) are routed along defined pathways by motor proteins that read address labels (adapter proteins) and deliver cargo to specified destinations.
The bus is not passive. It is actively maintained, dynamically remodeled, and directionally controlled. Microtubules are assembled and disassembled in response to cell signals. The transport network reconfigures itself during cell division, wound healing, and immune response. It is infrastructure that adapts to demand — a self-modifying network architecture.
Input/Output: The Cell Membrane
Every computing system interfaces with its environment through input and output channels. The cell's interface is its plasma membrane — a lipid bilayer approximately 7-8 nanometers thick that defines the boundary between the cell's interior and the external world.
The membrane is not a wall. It is a selectively permeable interface studded with thousands of specialized protein channels, receptors, transporters, and signaling complexes that control what enters, what exits, and what information the cell receives about its surroundings.
Receptor proteins are the input sensors. These are transmembrane proteins with an external domain that binds a specific signal molecule (hormone, growth factor, neurotransmitter, cytokine) and an internal domain that triggers a cascade of intracellular responses. The human cell surface carries hundreds of distinct receptor types, each tuned to a specific signal. When a hormone binds its receptor, the signal is transduced — converted from an extracellular chemical event to an intracellular signaling cascade that ultimately reaches the nucleus and modulates gene expression. This is analog-to-digital conversion: a chemical concentration gradient in the extracellular space is converted into a discrete, specific change in the cell's computational program.
Ion channels are gated ports. These are transmembrane proteins that open and close in response to voltage changes, mechanical stress, or ligand binding, allowing specific ions (sodium, potassium, calcium, chloride) to flow across the membrane. In neurons, voltage-gated ion channels generate the action potential — the digital signal that transmits information along nerve fibers at speeds up to 120 meters per second. This is the cell's data bus for long-range signaling.
Transport proteins manage the loading dock. These include pumps (active transport, requiring ATP) and carriers (facilitated diffusion) that move nutrients, waste products, and signaling molecules across the membrane. The sodium-potassium pump alone consumes approximately 25-30% of the cell's total ATP budget, maintaining the electrochemical gradient that powers neural signaling and secondary transport.
Cell-surface markers are the identity tags. MHC proteins (major histocompatibility complex), glycoproteins, and glycolipids on the cell surface identify the cell to the immune system — self versus non-self — and mediate cell-cell recognition, tissue organization, and immune surveillance.
The membrane is the cell's I/O layer — simultaneously a firewall (controlling access), a sensor array (detecting environmental signals), a communications interface (transmitting and receiving chemical messages), and an identity system (broadcasting cell type and status). No computing system operates without an I/O layer, and no cell operates without a functional membrane.
Integration
The components described in this section — processor (ribosome), instruction decoder (tRNA), program memory (mRNA), power supply (mitochondria), fabrication plant (ER), packaging and shipping (Golgi), transport network (cytoskeleton), and I/O layer (membrane) — are not independent modules that happened to end up in the same compartment. They are an integrated system in which every component depends on every other component for its own production, maintenance, and function.
Ribosomes manufacture every protein in the cell — including ribosomal proteins. tRNA molecules are loaded by synthetase enzymes that are themselves manufactured by ribosomes reading mRNA transcripts that were exported through nuclear pores built from proteins manufactured by ribosomes. Mitochondria produce the ATP that powers every other system, but mitochondrial proteins are manufactured by cytoplasmic ribosomes and imported via transport systems that require ATP to operate. The ER folds proteins that include the ER's own chaperones. The Golgi sorts and ships the very enzymes that maintain Golgi function.
Every component is both a product and a producer. The system manufactures itself from its own outputs. This is not a linear assembly line with a defined start and end. It is a closed, self-referential manufacturing loop in which the factory is its own product.
In computing terms, this is a self-compiling compiler — a system that produces its own machine code. The cell has the same dependency. The system runs self-referentially now. But it could not have assembled itself from raw components, because the assembly requires the very machinery that the assembly is supposed to produce. The bootstrap problem — how the first instance of this self-referential system came into existence — is the subject of Part 4.
For now, the observation is structural: the cell is a fully integrated hardware platform whose components are mutually dependent, self-manufacturing, and functionally analogous at every level to the hardware systems designed by human engineers — but operating at a scale of miniaturization, efficiency, and integration that no human engineering has approached.
Continue to Part 3 → How Does the Genome Work? – Part 3 of 5